Why your data platform doesn't have to cost a lot

The roadmap for data-driven transformation
The ePaper shows you strategies, success stories and a checklist for a direct start into the digital future.

Sound familiar? Months of planning. Six-figure budgets. Evaluation after evaluation, endless "what-if" scenarios, waiting forever for cloud approvals. And in the end? Your data project fails-not because of the technology, but because of its own complexity.
That's the bureaucratic overhead we've perfected in Germany. We hide behind "just one more evaluation" and "let's assess this again" because we're terrified of making the wrong decision.
But what if I told you: There's another way.
In his talk at TDWI virtual, our co-founder Mike Kamysz flipped this thinking on its head. He demonstrated a lean, production-ready open-source stack that-proven via live demo-runs on a single Raspberry Pi. No sales pitch. No vendor lock-in. No six-figure budget for infrastructure before you write the first line of code.
The recording is now online. For everyone who missed the live session, this post distills the key insights-and shows how we're taking a different path at The Data Institute.
or directly to YouTube: https://www.youtube.com/watch?v=GROfOhXR858
The Problem: We Let Perfect Become the Enemy of Good
Mike nailed it: Very few companies in Germany are such technological pioneers that they're solving challenges no other company in the world has tackled before.
Technology isn't the problem. The path to implementation is.
We create massive overhead:
- Months of evaluation before we even start
- Every possible use case must be mapped out on the drawing board
- Backup & disaster recovery strategies for... Excel files that marketing emails back and forth
"Do you really need a comprehensive backup and disaster recovery strategy just to replace the Excel files your marketing team emails back and forth?"
The result? Energy flows into projects for months until the entire team is burned out. And when approvals finally trickle in, no one believes anything will actually happen.
When Planning Makes Sense - And When It Doesn't
Let's be honest: we're consultants ourselves. We help companies from strategy through implementation. But that's exactly why we know from experience:
The difference lies in the "when" and "how much."
The question isn't whether you should plan. The question is: When do you plan what?
- ❌ The paralysis approach: Spend months thinking through every possible scenario before writing the first line of code
- ✅ The pragmatic approach: Start with an MVP, learn from it, then make informed plans for the next steps
There's a fundamental difference between:
- "We'll evaluate for 6 months to find the perfect solution" → Paralysis
- "We'll build a prototype in 2 weeks, then evaluate specifically what we need" → Progress
Good consulting accelerates this process. Bad consulting paralyzes you.
Mike, Sebastian, and I all worked in traditional consulting environments for years. We've witnessed the months-long evaluations. The PowerPoint battles. The projects that never made it past the planning phase. That's exactly why we founded The Data Institute—to show there's another way.
The Solution: Iteration First, Not Perfection First
The switch we need to flip: Build prototypes in days, not months.
No more abstract decisions based on unimaginable "what-if" scenarios. Instead: Build. Evaluate. Expand.
This isn't a new concept-many people know about MVPs (Minimal Viable Products). But Mike showed just how radically simple this can be in practice.
The Three Core Principles for any Stack
If any vendor tells you their tool is uniquely suited to solve your challenge-that's BS. There are countless technical paths that can lead to success.
What really matters: Your stack must fulfill three core principles.
1. Modularity: Best-of-Breed Over All-in-One
"There's no Swiss Army knife solution that does everything perfectly."
No tool in the world will ever perform all functions perfectly. All-in-one solutions almost always have significantly weaker features in at least one category.
Better to choose multiple tools that each solve one task perfectly and work well together-the classic best-of-breed approach.
The advantage: Swap out individual components as you outgrow them-without rebuilding the entire system.
2. Adoption: Python & SQL-Skills Actually Available in the Market
Not some exotic expert niche that only a handful of people worldwide can operate. Python and SQL-these are the most widespread data skills.
This makes it easy when you need to hire new people or upskill an existing team. No vendor training courses. Immediately applicable knowledge.
3. Independence: No Vendor Lock-in, No Hardware Constraints
True independence means: Hardware independence.
You should have the freedom to choose whether you run everything locally on your laptop, use a server sitting in some basement server room, or rent something in the cloud.
This flexibility allows you to grow organically-without locking yourself into restrictive contracts with SAP, Snowflake, Databricks, or anyone else.
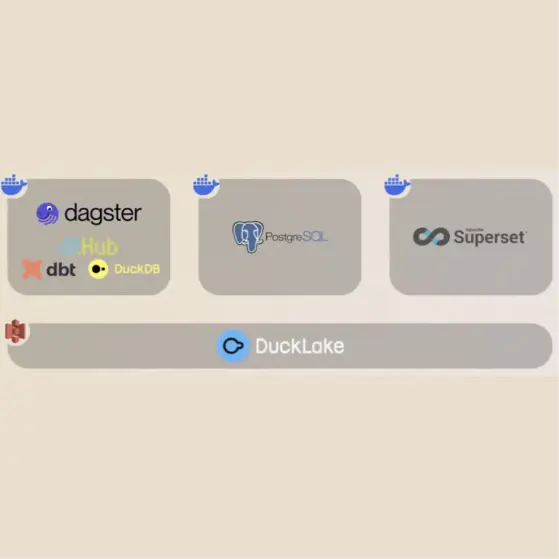
The Live Proof: Mike's Stack on a Raspberry Pi
What Mike showed at TDWI wasn't a concept. It was his real, production stack that we use at The Data Institute for our own data management:
- DLT (Data Load Tool) for integration
- dbt for transformation
- DuckDB as the compute engine
- Dagster for orchestration (with an "adorably cute logo," as Mike noted)
- Superset for visualization
The entire stack runs on a Raspberry Pi that Mike happened to have lying around.
"We don't need much. We just need to be able to run Python."
Three Docker containers. One repository. Runs identically on a MacBook, Raspberry Pi, or in the cloud.
A Concrete Example from the Talk
Mike demonstrated the integration of their ERP software (a tool for time tracking and project management):
The starting point:
- 6 API endpoints that need to be queried
- Data shouldn't be completely reloaded each time (incremental loading)
- Must be production-ready and robust
The result:
- 108 lines of code (including blank lines and documentation!)
- Parquet files automatically written to S3
- Ready for transformation with dbt
And the best part: DLT automatically handles many best practices like pagination and error handling. You don't have to build everything from scratch.
The Step-by-Step Journey: From Excel to Data Platform
Mike walked through a fictional but realistic example of how to progress step-by-step from manual processes to a data platform:
Step 1: Replace Excel as Your "Single Source of Truth"
- Instead of processing data in Excel formulas, use DuckDB
- Business rules are encoded in SQL
- Insights can still be output as Excel sheets for business users
Step 2: Eliminate Manual Downloads
- Standardized pipelines instead of copy & paste
- APIs and database connections instead of manual downloads
- This is where inconsistencies and quality issues become truly visible for the first time
Step 3: Introduce Simple Orchestration
- A simple cron job on an existing server is enough initially
- Python scripts process data automatically
- Results are written to a shared drive
Step 4: Develop a Company-Wide Data Model
- dbt comes into play for more complex transformations
- Dependencies between data are cleanly mapped
- Production and development environments are separated
Step 5: Professional Orchestration
- Dagster replaces the simple cron job
- Complex dependencies are centrally managed
- Coordinates different data sources with different update schedules
And that's where Mike stopped-because this is the stack we use productively ourselves.
How Far Can You Really Get With This?
The Honest Answer: Pretty Far. And That's Exactly the Point.
What we've learned ourselves—and share with you transparently:
- We haven't yet implemented this complete stack in a large enterprise customer project (it runs internally for us, and we use individual components in customer projects)
- DuckLake is partly Mike's "personal playground"—it's new and he wanted to experiment with it
- High availability and comprehensive disaster recovery? We don't have it in our internal stack because we don't need it yet
- If Mike's Raspberry Pi goes down, we simply restart the Docker containers—no problem for us
But that's exactly the point: We only build what we actually need. And we recommend you do the same.
When You'll Outgrow This Stack
DuckDB scales remarkably well on single nodes. But eventually, you might hit data volumes that require massive parallelization across multiple nodes.
Then you have several options:
1. Leverage modularity: DuckDB can write Iceberg tables. Simply swap out the compute engine (e.g., Spark) and keep the rest of the stack
2. Switch to commercial offerings: MotherDuck instead of self-hosting DuckLake, Dagster+ instead of self-hosting Dagster
3. Bring in DevOps expertise: If you genuinely have enterprise-level requirements (high availability, complex access management), you need additional expertise or switch to managed services
The key difference from drawing-board planning: You're no longer buying blind. You make informed decisions because you already know what works and where your real requirements lie.
How We Support You: Strategy + Rapid Implementation
At The Data Institute, we combine both:
Strategic Clarity – We help you ask the right questions and set priorities
+
Rapid Iteration – We build working prototypes with you in weeks, not months
Our 3-Step Approach:
1. Quick Assessment (1-2 Weeks)
- Where are you today? (Excel chaos, legacy systems, fragmented data?)
- What's the biggest pain point costing you time and sanity daily?
- Which use case delivers measurable value fastest?
2. MVP Build (2-4 Weeks)
- We build a working prototype together
- You see real results with your real data—not PowerPoint slides
- Technology stack based on the 3 core principles (modularity, adoption, independence)
3. Learn & Scale (Iterative)
- What did we learn? What works well, what needs adjustment?
- Where is further investment worthwhile?
- Next expansion stage or tackle other use cases?
The result: You make informed decisions based on real experience—not hypothetical drawing-board scenarios.
When External Support Makes Sense
You could theoretically do all this yourself. The tools are open source, documentation is available, YouTube tutorials exist.
But: You save months (and often costly mistakes) when you have someone who:
✅ Already uses the tools productively – We don't need to evaluate which tools work. We use them daily in our own stack
✅ Knows typical pitfalls – We've already learned the lessons: DuckDB performance tuning, dbt modeling with Kimball or Data Vault, Dagster scheduling gotchas, DLT configuration for various APIs
✅ Enables your team – We don't just build the platform and vanish. We work alongside your team (pair programming, hands-on workshops) and show them how to evolve the platform themselves
✅ Makes pragmatic decisions – When is open source enough? When is the commercial version worth it? When do you actually need a cloud solution? We have no vendor agenda and earn no commissions from tool recommendations
✅ Communicates honestly – Even if it means saying, "You don't need that" or "We're not the right fit for this"
The difference: We're not the consultants who'll write you 50 slides about "Strategic Data Platform Vision 2030." We're the ones who'll build your first working prototype with you next week.
Good consulting also means: Telling you what you DON'T need.
The Complete Talk + Additional Resources
Full presentation: Watch the complete talk "Data Stack in a Drawer – Modern Data Platforms: The Iteration-First Approach" on YouTube and experience the live demo of the Raspberry Pi stack.
In the talk, you'll also learn:
- How Mike specifically configured the three Docker containers
- The detailed data flow from API through dbt to visualization
- Answers to questions about permission management, scalability, and high availability
- Why Dagster has "the cutest logo" (yes, really)
More Modern Data Engineering Insights: On our blog, we regularly share our knowledge about DLT, dbt, DuckDB, and show you what the path from Excel to an automated data platform actually looks like.
BROWSE OUR BLOG | SUBSCRIBE TO NEWSLETTER
Ready to Flip the Switch?
Had enough of months of planning with no results? Ready to start building instead of endless evaluation?
Book a free 30-minute initial consultation with us. We'll analyze your starting point and show you concretely how to begin your first MVP cycle—pragmatically, without vendor lock-in, and with measurable value in weeks instead of months.
What We Take Away from the Talk
1. Start now—not after the tenth evaluation
2. Use open source—stay independent and flexible
3. Grow organically—add tools when you actually need them
4. Make informed decisions—based on real experience with your real data, not hypotheses
The best time to start your data platform was yesterday. The second-best time is today—with a working MVP instead of a perfect plan.
Don't miss an update
And subscribe directly to our monthly newsletter.
Don't miss an update
And subscribe directly to our monthly newsletter.
Don't miss an update
And subscribe directly to our monthly newsletter.
Related case studies
There are suitable case studies on this topic
Which services fit this topic?