Warum Ihre Datenplattform nicht viel kosten muss

Der Fahrplan für datengetriebene Transformation
Das ePaper zeigt dir Strategien, Erfolgsbeispiele und eine Checkliste für den direkten Start in die digitale Zukunft.

Kennen Sie das auch? Monatelang Planung. Budgets im sechsstelligen Bereich. Evaluation, "Was-wäre-wenn"-Szenarien, endlose Wartezeiten auf Cloud-Freigaben. Und am Ende? Das Datenprojekt scheitert - nicht an der Technologie, sondern an seiner eigenen Komplexität.
Das ist der Wasserkopf, den wir in Deutschland lieben. Wir verstecken uns hinter "noch einer Evaluation" und "hier noch eine Bewertung", weil wir eine ziemlich große Angst davor haben, die falsche Entscheidung zu treffen.
Aber was, wenn ich Ihnen sage: Es geht anders.
In seinem Vortrag auf der TDWI virtual hat unser Co-Founder Mike Kamysz dieses Denken auf den Kopf gestellt. Er zeigte einen schlanken, produktionsreifen Open-Source-Stack, der - bewiesen am Live-Beispiel - auf einem einzigen Raspberry Pi läuft. Kein Sales-Pitch. Kein Vendor Lock-in. Keine tausende von Euro für Infrastruktur, bevor die erste Zeile Code geschrieben wird.
Die Aufzeichnung ist jetzt online. Für alle, die den Live-Termin verpasst haben, liefert dieser Blogpost die wichtigsten Insights - und zeigt, wie wir bei The Data Institute einen anderen Weg gehen.
oder direkt zu YouTube: https://www.youtube.com/watch?v=GROfOhXR858
Das Problem: Wir lassen das Perfekte zum Feind des Guten werden
Mike brachte es auf den Punkt: Die wenigsten Firmen in Deutschland sind solche technologischen Vorreiter, dass sie Herausforderungen bewältigen müssen, die noch kein anderes Unternehmen auf der Welt vor ihnen gelöst hat.
Die Technik ist längst nicht das Problem. Der Weg zur Implementierung ist es.
Wir bauen einen riesigen Wasserkopf:
- Monatelange Evaluationen, bevor wir überhaupt anfangen
- Jeder mögliche Use Case muss am Reißbrett mitgedacht werden
- Backup & Disaster Recovery Strategien für... Excel-Dateien, die sich das Marketing per E-Mail hin und her schickt
"Braucht man wirklich sowas wie eine Backup- und Disaster Recovery Strategie, um die Excel-Dateien abzulösen, die sich das Marketing-Team per Mail hin und her schickt?"
Das Ergebnis? Monatelang fließen Kraft und Energie in Projekte, bis das gesamte Team ausgebrannt ist. Und wenn dann endlich die ersten Freigaben eintrudeln, glaubt niemand mehr daran, dass sich irgendwann mal was tut.
Wann Planung Sinn macht - und wann nicht
Lassen Sie uns ehrlich sein: Wir sind selbst Berater. Wir begleiten Unternehmen von der Strategie bis zur Implementierung. Aber genau deshalb wissen wir aus eigener Erfahrung:
Der Unterschied liegt im "Wann" und "Wie viel".
Die Frage ist nicht, ob Sie planen sollten. Die Frage ist: Wann planen Sie was?
- ❌ Der lähmende Ansatz: Monatelang alle möglichen Szenarien durchdenken, bevor Sie die erste Zeile Code schreiben
- ✅ Der pragmatische Ansatz: Mit einem MVP starten, daraus lernen, und dann informiert die nächsten Schritte planen
Es gibt einen fundamentalen Unterschied zwischen:
- "Wir evaluieren 6 Monate, um die perfekte Lösung zu finden" → Lähmung
- "Wir bauen 2 Wochen einen Prototyp, evaluieren dann konkret, was wir brauchen" → Fortschritt
Gute Beratung beschleunigt diesen Prozess. Schlechte Beratung verzögert ihn.
Mike, Thomas und ich haben alle lange in klassischen Beratungsumfeldern gearbeitet. Wir haben monatelange Evaluationen miterlebt. Die PowerPoint-Schlachten. Die Projekte, die nie über die Planungsphase hinaus kamen. Genau deshalb haben wir The Data Institute gegründet - um zu zeigen, dass es anders geht.
Die Lösung: Iteration First statt Perfection First
Der Schalter, den wir umlegen müssen: Prototypen in ein paar Tagen bauen, statt monatelang Ressourcen zu investieren.
Keine abstrakten Entscheidungen mehr anhand unvorstellbarer "Was-wäre-wenn"-Szenarien. Stattdessen: Bauen. Bewerten. Ausbauen.
Das ist kein neues Konzept - das MVP (Minimal Viable Product) kennen viele. Aber Mike hat gezeigt, wie radikal einfach das in der Praxis aussehen kann.
Die drei Kernprinzipien für jeden Stack
Wenn Ihnen irgendwelche Vendoren erzählen, dass ihr Tool einzigartig geeignet ist, um Ihre Herausforderung zu lösen - das ist gelogen. Es gibt in der Technik super viele Wege, die nach oben führen können.
Was wirklich zählt: Ihr Stack muss drei Kernprinzipien erfüllen.
1. Modularität: Best-of-Breed statt All-in-One
"Diese eierlegende Wollmilchsau gibt es nicht."
Kein Tool der Welt wird jemals alle Funktionen perfekt erfüllen können. All-in-One-Lösungen haben fast immer in mindestens einer Kategorie schlechte Funktionen.
Wählen Sie lieber mehrere Tools, die eine Aufgabe perfekt lösen und gut zusammenarbeiten - den klassischen Best-of-Breed-Ansatz.
Der Vorteil: Einzelne Komponenten austauschen, wenn Sie aus ihnen herausgewachsen sind - ohne das ganze System neu bauen zu müssen.
2. Verbreitung: Python & SQL - Skills, die am Markt verfügbar sind
Keine exotische Expertennische, die nur eine Handvoll Menschen weltweit bedienen kann. Python und SQL - das sind die meistverbreiteten Data-Skills.
Das macht es leicht, wenn Sie neue Leute einstellen müssen oder ein bestehendes Team befähigen wollen. Keine Vendor-Trainings. Direkt anwendbares Wissen.
3. Unabhängigkeit: Kein Vendor Lock-in, keine Hardware-Fesseln
Echte Unabhängigkeit bedeutet: Hardware-Unabhängigkeit.
Es sollte Ihnen freistehen, ob Sie alles lokal auf Ihrem Computer machen, ob Sie einen Server nutzen, der irgendwo im Firmenkeller rumsteht, oder ob Sie etwas in der Cloud anmieten.
Diese Flexibilität erlaubt es Ihnen, organisch zu wachsen - ohne sich Knebelverträge mit SAP, Snowflake, Databricks oder wem auch immer aufzwingen zu lassen.
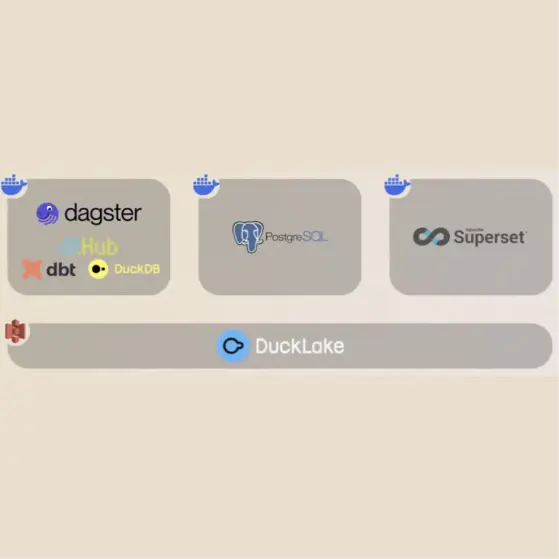
Der Live-Beweis: Mikes Stack auf dem Raspberry Pi
Was Mike auf der TDWI zeigte, war kein Konzept. Es war sein echter, produktiver Stack, mit dem wir bei The Data Institute unser eigenes Datenmanagement machen:
- DLT (Data Load Tool) für die Integration
- dbt für die Transformation
- DuckDB als Compute Engine
- Dagster für die Orchestrierung (mit "wahnsinnig süßem Logo", wie Mike anmerkte)
- Superset für die Visualisierung
Das Ganze läuft auf einem Raspberry Pi, den Mike im Schreibtisch rumliegen hatte.
"Wir brauchen nicht viel. Wir müssen nur Python ausführen können."
Drei Docker-Container. Ein Repository. Läuft genauso auf dem MacBook, dem Raspberry Pi oder in der Cloud.
Ein konkretes Beispiel aus dem Talk
Mike zeigte die Integration ihrer ERP-Software (ein Tool für Zeitbuchungen und Projektmanagement):
Die Ausgangslage:
- 6 API-Endpoints, die abgefragt werden müssen
- Daten sollen nicht jedes Mal komplett neu geladen werden (inkrementelle Beladung)
- Muss produktionsreif und robust sein
Das Ergebnis:
- 108 Zeilen Code (inklusive Leerzeilen und Dokumentation!)
- Parquet-Files werden automatisch nach S3 geschrieben
- Bereit für die Transformation mit dbt
Und das Beste: DLT impliziert automatisch viele Best Practices wie Pagination und Error Handling. Sie müssen nicht alles von Hand bauen.
Der schrittweise Aufbau: Von Excel zur Datenplattform
Mike führte durch ein fiktives, aber realistisches Beispiel, wie man Schritt für Schritt von manuellen Prozessen zur Datenplattform kommt:
Schritt 1: Excel als "Single Source of Truth" ablösen
- Statt Daten in Excel-Formeln zu verarbeiten, nutzen Sie DuckDB
- Business-Regeln werden in SQL abgebildet
- Insights können weiterhin in Excel-Sheets für Fachbereiche ausgegeben werden
Schritt 2: Manuelle Downloads eliminieren
- Standardisierte Pipelines statt Copy & Paste
- APIs und Datenbankverbindungen statt manueller Downloads
- Hier werden Inkonsistenzen und Qualitätsprobleme erstmals wirklich sichtbar
Schritt 3: Einfache Orchestrierung einführen
- Ein simpler Cron-Job auf einem vorhandenen Server reicht am Anfang
- Python-Scripts verarbeiten Daten automatisch
- Ergebnisse werden in ein geteiltes Laufwerk geschrieben
Schritt 4: Unternehmensweites Datenmodell entwickeln
- dbt kommt ins Spiel für komplexere Transformationen
- Abhängigkeiten zwischen Daten werden sauber abgebildet
- Produktions- und Entwicklungsumgebung werden getrennt
Schritt 5: Professionelle Orchestrierung
- Dagster ersetzt den einfachen Cron-Job
- Komplexe Abhängigkeiten werden zentral gesteuert
- Verschiedene Datenquellen mit unterschiedlichen Aktualisierungszeiten koordiniert
Und genau hier hörte Mike auf - weil das der Stack ist, den wir selbst produktiv nutzen.
Wie weit kommt man damit wirklich?
Die ehrliche Antwort: Ziemlich weit. Und das ist der Punkt.
Was wir selbst gelernt haben - und transparent mit Ihnen teilen:
- Wir haben diesen kompletten Stack noch nicht in einem großen Kundenprojekt im Enterprise-Kontext implementiert (er läuft bei uns intern und einzelne Komponenten nutzen wir in Kundenprojekten)
- DuckLake ist teilweise "persönliche Spielerei", weil es neu ist und Mike damit experimentieren wollte
- High Availability und umfassendes Disaster Recovery? Haben wir in unserem internen Stack nicht, weil wir es noch nicht brauchen
- Wenn Mike's Raspberry Pi mal ausfällt, setzen wir die Docker-Container einfach neu auf - für uns kein Problem
Aber genau das ist der Punkt: Wir bauen nur das, was wir wirklich brauchen. Und das Gleiche empfehlen wir Ihnen.
Wann Sie aus diesem Stack herauswachsen
DuckDB skaliert massiv gut auf einzelnen Nodes. Aber irgendwann könnten Sie auf Datenmengen stoßen, die massive Parallelisierung über mehrere Nodes erfordern.
Dann haben Sie mehrere Optionen:
1. Modularität nutzen: DuckDB kann Iceberg Tables schreiben. Tauschen Sie einfach die Compute Engine aus (z.B. Spark) und behalten Sie den Rest des Stacks
2. Auf kommerzielle Angebote wechseln: MotherDuck statt DuckLake selbst zu hosten, Dagster+ statt Dagster selbst zu betreiben
3. DevOps-Expertise hinzuziehen: Wenn Sie wirklich Enterprise-Level Anforderungen haben (High Availability, komplexes Access Management), brauchen Sie zusätzliche Expertise oder wechseln zu Managed Services
Der wesentliche Unterschied zur Planung am Reißbrett: Sie kaufen nicht mehr die Katze im Sack. Sie treffen informierte Entscheidungen, weil Sie bereits wissen, was funktioniert und wo Ihre echten Anforderungen liegen.
So begleiten wir Sie: Strategie + schnelle Umsetzung
Bei The Data Institute verbinden wir beides:
Strategische Klarheit - Wir helfen Ihnen, die richtigen Fragen zu stellen und Prioritäten zu setzen
+
Schnelle Iteration - Wir bauen mit Ihnen funktionierende Prototypen in Wochen, nicht Monaten
Unser Ansatz in 3 Schritten:
1. Quick Assessment (2 Wochen)
- Wo stehen Sie heute? (Excel-Chaos, Legacy-Systeme, fragmentierte Daten?)
- Was ist der größte Pain Point, der Sie täglich Zeit und Nerven kostet?
- Welcher Use Case liefert am schnellsten messbaren Mehrwert?
2. MVP Build (2-4 Wochen)
- Wir bauen gemeinsam einen funktionierenden Prototyp
- Sie sehen echte Ergebnisse mit Ihren echten Daten - keine PowerPoint-Slides
- Technologie-Stack basierend auf den 3 Kernprinzipien (Modularität, Verbreitung, Unabhängigkeit)
3. Learn & Scale (iterativ)
- Was haben wir gelernt? Was funktioniert gut, was muss angepasst werden?
- Wo lohnt sich weiteres Investment?
- Nächste Ausbaustufe oder andere Use Cases angehen?
Das Ergebnis: Sie treffen informierte Entscheidungen basierend auf echten Erfahrungen - nicht auf hypothetischen Szenarien am Reißbrett.
Wann externe Unterstützung Sinn macht
Sie könnten das theoretisch alles selbst machen. Die Tools sind Open Source, die Dokumentation ist verfügbar, YouTube-Tutorials gibt es auch.
Aber: Sie sparen Monate (und oft auch Fehlentscheidungen), wenn Sie jemanden haben, der:
✅ Die Tools bereits produktiv nutzt - Wir müssen nicht erst evaluieren, welche Tools funktionieren. Wir nutzen sie selbst täglich in unserem eigenen Stack
✅ Typische Fehler kennt - Wir haben die Learnings bereits durchgemacht: DuckDB-Performance-Tuning, dbt-Modellierung nach Kimball oder Data Vault, Dagster-Scheduling-Fallstricke, DLT-Konfiguration für verschiedene APIs
✅ Ihr Team befähigt - Wir bauen nicht nur die Plattform und verschwinden dann. Wir arbeiten mit Ihrem Team zusammen (Pair Programming, Hands-on-Workshops) und zeigen ihnen, wie sie die Plattform selbst weiterentwickeln können
✅ Pragmatische Entscheidungen trifft - Wann reicht Open Source? Wann lohnt sich die kommerzielle Variante? Wann brauchen Sie wirklich eine Cloud-Lösung? Wir haben keine Vendor-Agenda und verdienen keine Provisionen an Tool-Empfehlungen
✅ Ehrlich kommuniziert - Auch wenn es bedeutet zu sagen: "Das brauchen Sie nicht" oder "Dafür sind wir nicht die Richtigen"
Der Unterschied: Wir sind nicht die Berater, die Ihnen 50 Slides über "Strategic Data Platform Vision 2030" schreiben. Wir sind die, die mit Ihnen nächste Woche den ersten Prototyp bauen.
Gute Beratung bedeutet auch: Zu sagen, was Sie NICHT brauchen.
Der komplette Talk + weiterführende Ressourcen
Vollständiger Vortrag: Schauen Sie sich den kompletten Talk "Data Stack in a drawer - Moderne Datenplattformen: Der Iteration-First-Ansatz" auf YouTube an und erleben Sie die Live-Demo des Raspberry-Pi-Stacks.
LINK ZUM YOUTUBE-VIDEO: https://www.youtube.com/watch?v=GROfOhXR858
Im Talk erfahren Sie außerdem:
- Wie Mike die drei Docker-Container konkret konfiguriert hat
- Den detaillierten Datenfluss von der API über dbt bis zur Visualisierung
- Antworten auf Fragen zu Permission Management, Skalierbarkeit und High Availability
- Warum Dagster "das süßeste Logo" hat (ja, wirklich)
Mehr Insights zu Modern Data Engineering: In unserem Blog teilen wir regelmäßig unser Wissen zu DLT, dbt, DuckDB und zeigen Ihnen, wie der Weg von Excel zur automatisierten Datenplattform konkret aussieht.
BLOG DURCHSTÖBERN | NEWSLETTER ABONNIEREN
Bereit, den Schalter umzulegen?
Sie haben genug von monatelangen Planungen ohne Ergebnisse? Sie wollen endlich anfangen statt zu evaluieren?
Vereinbaren Sie ein kostenloses 30-minütiges Erstgespräch mit uns. Wir analysieren Ihre Ausgangslage und zeigen Ihnen konkret, wie Sie mit dem ersten MVP-Zyklus beginnen können - pragmatisch, ohne Vendor Lock-in und mit messbarem Mehrwert in Wochen statt Monaten.
Was wir aus dem Talk mitnehmen
1. Starten Sie jetzt - nicht nach der zehnten Evaluation
2. Nutzen Sie Open Source - bleiben Sie unabhängig und flexibel
3. Wachsen Sie organisch - fügen Sie Tools hinzu, wenn Sie sie wirklich brauchen
4. Treffen Sie informierte Entscheidungen - basierend auf echten Erfahrungen mit Ihren echten Daten, nicht auf Hypothesen
Die beste Zeit, um mit Ihrer Datenplattform zu starten, war gestern. Die zweitbeste Zeit ist heute - mit einem funktionierenden MVP statt einem perfekten Plan.
Kein Update verpassen
Und direkt unseren monatlichen Newsletter abonnieren.
Kein Update verpassen
Und direkt unseren monatlichen Newsletter abonnieren.
Kein Update verpassen
Und direkt unseren monatlichen Newsletter abonnieren.
Passende Case Studies
Zu diesem Thema gibt es passende Case Studies
Welche Leistungen passen zu diesem Thema?