The minimalistic data stack


The roadmap for data-driven transformation
The ePaper shows you strategies, success stories and a checklist for a direct start into the digital future.

This series aims to build a fully functional yet lightweight data platform that primarily uses open-source tools and scales from prototype to enterprise application. Mike also shares his knowledge on Medium at https://perspectives.datainstitute.io/
Series overview:
- Part 1: The basics of the minimalistic data stack (this part)
- Part 2: Setting up integration pipelines
- Part 3: Automate integration and writing to storage
- Part 4: Design and implement your data model
- Part 5: Add documentation and observability (in preparation)
The challenge: confusion instead of clarity
Have you stumbled across any of the State of Data Engineering Maps maps recently? From tools long deemed dead to niche names you’ve never heard of: The sheer amount of logos in these things is enough to get even the most seasoned industry veteran’s head spinning.
Now put yourself in the shoes of someone who is just starting out. A team that sees the promise of making their data more available and thus actionable. You hack “How to become data-driven?” into the search engine of your choice. The term Modern Data Stack flickers across your screen. And before you realize what’s happening, you stare down the barrel of a mid to high five figure proof of concept, wrapped into a shiny pitch deck by a consultant just a tad too excited to be believable. Did they mention yet how AI is going to unlock your business’ true potential?
Who this guide is for
Most of our client work happens in and around Germany. Small and medium enterprises make up a whopping 99% of all companies here. They employ more than half the country’s workforce and generate a quarter of total revenue (source). These companies are not at the cutting edge of data use cases. They have no use for the latest FAANG technology. Their main concern is either a modernization of legacy systems or finally having reliable automated access to data they painstakingly have to collect manually today.
This story is a starting point for precisely this audience. We will focus on what is essential. We will highlight pitfalls and traps to avoid. You’ll be able to recognize vendor bla-bla the next time it’s shoved down your throat. Instead of getting blindsided by the latest buzzwords, you’ll have learned about a toolset that has:
- Easy setup and easy maintenance
- Minimal costs with high usability
- Scalability and the ability to grow with your use cases
- Minimal vendor lock-in
Let's call it the Minimalist data stack.

The essential functions and non-negotiables
Behind all the buzzwords, the purpose of a data platform has remained unchanged since the Inmons of this world started developing the concept of Data Warehousing in the 1980s.
At it’s core, we want to move data out of various operational systems into a centralized storage, where it’s persisted, cleaned, and transformed according to our business rules, and then exposed to consumers for further use. This simple breakdown allows us to reduce the components of our data platform to the bare minimum:
1. Data integration (data integration)
2. Data storage (data storage)
3. Data transformation (data transformation)

The indispensable components (Non-Negotiables)
Beyond that is a class of tools we shall call the non-negotiables. They are not strictly necessary, in a sense where a data platform will still be recognizable and operational without them. But if we consider the core three functions our foundation, then the non-negotiables are the structural support allowing us to build more than one story high. Only through them are we able to achieve our goal of a maintainable, scalable and extendable data platform.
Add to the mix then: Version Control, Documentation, and Monitoring.

Six components to give you the most robust start possible. If you were to add to it, you’d introduce additional complexity that makes the beginning of your journey harder. If you were to take away from it, the integrity of the platform would risk a major hit. In Antoine de Saint-Exupery´s eyes, thats perfection
Why you should stay away from complete solutions
There are vendors out there who will try to convince you that their solution is able to cover all your current and future needs, and there are a million of them out there. Be it Microsoft’s push for Fabric, platforms such as Rivery or Y42, or industry-specific solutions such as Klar, many solutions exist that can get you started very quickly. Either, these tools come as no- or low-code applications that allow you to drag & drop your pipelines and transformations, or they provide an execution environment, orchestration and observability for the pipelines you have coded.
The promises these vendors make are intriguing. But in reality, I have seen the downfalls of these platforms one too many times in order to recommend anyone using them.
The issues with No- and Low-Code solutions
The theory of allowing non-data-experts to set up integrations and transformations easily and quickly sounds good. Who hasn’t worked in a company where the IT department was a bottleneck and struggling to keep up with tickets? If the teams relying on the data can procure it themselves, that sounds like a good idea on paper.
But when you think about it, having non-data-experts in charge of your data platform doesn’t sound so good anymore. Sure, a small automation of previously manual copy and paste jobs in Excel sheets might be doable. But beyond that, these tools just don’t scale well.
Having crucial transformation logic and business rules tucked away behind layers and layers of visual building blocks is simply not feasible when building a serious platform aiming to serve more than just one niche use case. Couple that with often lacking features urgently needed when collaborating on data, such as version history or automated deployment checks, and you have a recipe for disaster.
The final nail in the coffin comes in the form of lock-in effects. When you’ve relied on one platform’s visual building blocks to build your entire business intelligence, swapping away from that tool for any reason becomes a dreaded task, as you get to rebuild everything in whatever tool you use next.
The issue with “end-to-end” platforms
Any platform that allows you to run your own code is a step in the right direction. When your data assets are defined in code that you own, migrating to another platform that allows you to run it, will be orders of magnitude easier, quicker, and cheaper.
Still, for every other function that this turnkey solution provides you with, the lock-in effect remains. If your entire ability to discover and document data within your company rests on one yearly subscription, you better hope they don’t raise their prices.
Also, do you really want to bet on one vendor knocking it out of the park with every single function of your data platform and providing the best possible solution? Not even the big names get close to it. Microsoft’s Fabric, while cleverly marketed and undoubtedly successfully sold, is notorious for how poorly received it is in the Data Engineering community. Even the tool’s own Subreddit is not holding back. You will have a much more pleasant experience using a modular composition of tools proven to work well together.
The skillset required to build a data platform
Even with the advance of AI agents and vibe coding, building and maintaining a data platform does require a specific skillset. Take this Reddit thread as an example for why Claude and Co. are not coming for Data Engineering jobs just yet.
So while not anyone can just get a data platform up and running without putting in the work, anyone can learn how to do it. And since we’re setting out to start with as little complexity as possible (while still maintaining a scalable foundation), it is less of a challenge than you might think.
SQL, the query language that first saw the light of day as Marvin Gaye started suggesting to get it on more than 50 years ago, still remains the most important skill when working with data. In the Minimalist’s Data Stack, it will be used to transform data and apply business rules.
Second to SQL comes Python. When you want to move data out of operational tools into a data platform, sooner rather than later you will come across tools which don’t support automated exports of data to the destination of your choice. In these cases you have two options. One is utilizing tailored applications that take care of moving data for you. These are either costly or require administration and hosting efforts. The second option is coding pipelines yourself. While this can be done using many programming languages, Python is the choice for most.
While neither SQL nor Python are easy to master, both belong to the easier programming languages to pick up. As such, they are wildly popular and with this popularity come abundant resources to learn and practice. These skills are also easy to hire for. A criterion not to be neglected when setting out to build a data platform, as you might just be successful enough to grow a proper data team down the road.
Last but certainly not least, some familiarity with data modeling is required. Very rarely does raw data yield what we want from it. As we start combining data from multiple sources into one central data repository for our business, it is important to make sure that the puzzle pieces fit. As data volume grows, a solid data model makes sure that we can still query our data efficiently. It is the backbone for high data quality and reliable insights.
The tools that power our essential functions
Having covered the theory, it is time to start putting together the architecture that will build the foundation of our data stack.
All of the tools are battle-tested in large data projects. They are market staples for a reason. And the wonderful thing is that they work just as well for someone starting out. With this foundation you will have everything you need to grow.
Data integration
We could use turnkey solutions for data integration. The market has spawned plenty of options, from enterprise-grade tools such as Fivetran to open source alternatives like Airbyte. These tools have minor caveats, such as each of them applying their own individual schema to integrated data, which makes switching between tools difficult. But they also come with larger downsides: Paid tools are pricey and make you dependent on the vendor, open source tools require self-hosting which can get complex when you want to make sure that proper security is maintained.
Because of that, we will write our pipelines ourselves. This sounds daunting, but by making use of Python libraries to move data, we can shave of a significant of time and effort. Our tool of choice will be dltHub.
With dlt we benefit from full flexibility and pre-made connectors that allow us to move data from sources to destinations fast. There are existing connections for any common SQL database, REST APIs and a number of common operational applications, such as Salesforce, Shopify, Google Analytics or Facebook Ads. With these, you’re ready to move data in minutes. The tool also takes care of all the complicated stuff, such as handling updated data and incremental loads.
dlt is open source. Your pipelines are Python. As such, you can run them wherever you like. Neat!
Data transformation
Code is king, also when it comes to data transformations. We want to explicitly define what’s going to happen to our data as it moves through the data warehouse. We achieve this with dbt.
dbt is SQL on steroids. It allows us to focus on writing the SELECT statements that define how our data looks, and takes care of creating the tables, views, and columns that are necessary for that. All of the transformation happens within our data storage.
Just as dlt does for integration pipelines, dbt handles the complexity in our transformation processes. Updating data, keeping track of changes, handling dependencies between objects. All of it happens behind the curtain, but it gives the curious mind all the control to pull it aside to see and have a say in what is happening.
It’s open source. It’s a command line tool that executes SQL statements in the data storage of your choice. You can run it anywhere. Neat again!
Data Storage
When setting out to build a data platform, the place that stores and computes your data seems like the most important part of it all. You might be surprised that in reality, this is the most trivial choice to make in the Minimalist’s Data Stack. Ask one of your colleagues to pick a number between one and three. One, you go with Databricks. Two, Snowflake will be your choice. And because it rhymes, three means Google BigQuery.
Of course this is grossly simplified and everyone will have their own favorite. But in terms of usability, capability and compatibility, all three are playing in the same league.
Some companies might have a preferred cloud provider (Google Cloud Platform, Microsoft Azure or Amazon Web Services), which might impact the choice. Databricks and Snowflake are independent and work in all three. BigQuery is only available on GCP.
All three have some form of free credits or free tier, but from experience, BigQuery has the most generous one. In fact, odds are good that your first use case might stay well below the free limits (10GB storage, 1TB processing per month).
Bringing in the non-negotiables
The basic building blocks are covered. But with a few additions, we can make sure that what we’re building now, will still remain performant and pleasant to work with down the line.
Version Control
Since all our assets are defined in code, version control is a must have. It allows us to have a full history of all changes ever made. We can develop and test without fear of breaking our production state. And when we’ve hit a dead-end, we can go back to the original state and try again.
If you’ve ever worked in a tool that doesn’t have it, you will know the nerve wrecking feeling of having to save changes that will directly affect your production systems without the chance of rolling back. No, thank you.
We’re going to use GitHub as our version control of choice.
Documentation
Remember how we have set out to create a clutter-free data stack? The great thing about our tool choices so far, is that they’re capable of handling some of the non-negotiables themselves.
dbt has great documentation features. You can visualize lineages to illustrate where data is coming from and where it is used. You can add descriptions to tables and the attributes and metrics they contain. You can categorize data with tags, and you can add any freely configurable metadata to your models.
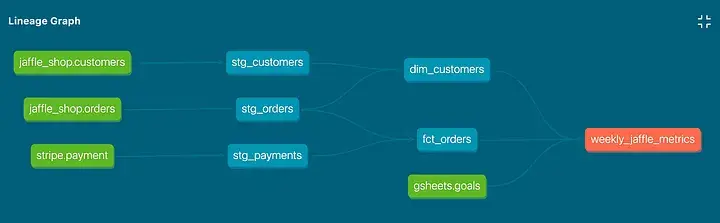
All of this is easily shareable with your stakeholders, as dbt packages all of this up into a neat HTML page that can easily be hosted.
Monitoring
When data is used to influence decisions or guide processes, it is critical that data can be trusted. You will need to stay on top of potential issues.
Again, our tool choices help us to stay lean and avoid tool bloat. dbt can be extended with community-built packages. One such package is dbt-elementary.
In essence, it uses the logs dbt creates when running and stores them alongside your data in storage. With this history of logs, it keeps track of execution times, model failures and test coverage. It even allows you to setup advanced tests to detect anomalies in model execution time, data volume and even on column-level.
All of these insights can be sent directly through communication channels like Slack or Teams and hosted through HTML.

Bringing it all together
The very observant of you might have noticed that so far, we haven’t covered one crucial aspect of a data stack, and that is where it actually runs. How are our data integration pipelines scheduled and executed? How will our dbt models be invoked?
Since we’re keeping it easy and lean, this is yet again an opportunity to multi-purpose tools we’ve already been using.
GitHub not only provides us with the repository in which we keep and version all of our code. It also comes with a wonderful thing called GitHub Actions.
GitHub Actions provide you with a customizable runtime environment to execute code, meaning that we can run Python scripts and call command line tools, such as dbt. They can be set up to run on triggers or timed schedules. Ideal for our use case. We will utilize GitHub Actions to both run our data integration Python scripts, as well as call dbt to model our data once it hit the data warehouse.
Every repository comes with a generous amount of free usage for GitHub actions. It all depends on the frequency and volume of your data, but if we batch process data once a day to feed a couple reporting dashboards, we will stay well within the free tier for sure.
What’s next?
By now you should have a solid overview over the components that are essential to build a data platform. You have learned about a tool stack that is ideal to get you started, while flexible enough to cover all your requirements as you grow beyond your initial use cases. Due to its modular nature, tools can be swapped out easily, when alternatives better fill your needs. And as we are relying on established solutions, they play well with other tools and platforms, too. Yes, even AI use cases will be no problem, once you’ve built the solid foundation.
But the theory is only one thing. Where it really starts to get interesting is actual, hands-on implementation. And since we’re eager to help get you started, the next posts in these series will focus on just that.
Read the second post about integrating data using dlt here.
Schedule your free expert consultation now and let us develop your individual data stack roadmap together.
Ready for your minimalistic data stack?
Whether it's data integration with dlt, transformations with dbt, or the complete architecture — The Data Institute helps German SMEs build lean and scalable data platforms without unnecessary overgrowth of tools. Schedule your free strategy meeting now.Repeat
Ready for your minimalistic data stack?
Whether it's data integration with dlt, transformations with dbt, or the complete architecture — The Data Institute helps German SMEs build lean and scalable data platforms without unnecessary overgrowth of tools. Schedule your free strategy meeting now.Repeat
Ready for your minimalistic data stack?
Whether it's data integration with dlt, transformations with dbt, or the complete architecture — The Data Institute helps German SMEs build lean and scalable data platforms without unnecessary overgrowth of tools. Schedule your free strategy meeting now.Repeat
Related case studies
There are suitable case studies on this topic


