Der Minimalistische Data Stack


Der Fahrplan für datengetriebene Transformation
Das ePaper zeigt dir Strategien, Erfolgsbeispiele und eine Checkliste für den direkten Start in die digitale Zukunft.

Diese Serie zielt darauf ab, eine voll funktionsfähige und dennoch schlanke Datenplattform aufzubauen, die hauptsächlich Open-Source-Tools nutzt und vom Prototyp bis zur Unternehmensanwendung skaliert. Mike teilt sein Wissen auch auf Medium unter https://perspectives.datainstitute.io/
Serie-Überblick:
- Teil 1: Die Grundlagen des Minimalistischen Data Stacks (dieser Teil)
- Teil 2: Einrichtung von Integrations-Pipelines
- Teil 3: Automatisierung der Integration und Schreiben in den Speicher
- Teil 4: Gestaltung und Implementierung Ihres Datenmodells
- Teil 5: Hinzufügen von Dokumentation und Observability (in Vorbereitung)
Die Herausforderung: Verwirrung statt Klarheit
Bist Du kürzlich über eine der State of Data Engineering Maps gestolpert? Von längst totgeglaubten Tools bis hin zu Nischen-Namen, von denen Du noch nie gehört hast: Die schiere Menge an Logos in diesen Übersichten bringt selbst erfahrene Branchenveteranen ins Straucheln.
Versetze Dich nun in die Lage eines Einsteigers. Ein Team, das das Versprechen erkennt, seine Daten verfügbarer und damit handlungsfähiger zu machen. Du hackst "Wie wird man datengetrieben?" in die Suchmaschine Deiner Wahl. Der Begriff Modern Data Stack flackert über Ihren Bildschirm. Und bevor Du realisierst, was passiert, starrst Du auf ein fünf- bis sechsstelliges Proof of Concept, verpackt in eine glänzende Pitch-Präsentation von einem Berater, der ein bisschen zu aufgeregt ist, um glaubwürdig zu sein. Hat er schon erwähnt, wie KI das wahre Potenzial Ihres Unternehmens freisetzen wird?
Für wen dieser Guide gedacht ist
Der Großteil unserer Beratungsarbeit findet in und um Deutschland statt. Kleine und mittelständische Unternehmen machen hier beeindruckende 99% aller Firmen aus. Sie beschäftigen mehr als die Hälfte der Arbeitskräfte des Landes und erwirtschaften ein Viertel des Gesamtumsatzes (Quelle).
Diese Unternehmen stehen nicht an der Spitze innovativer Data Use Cases. Sie haben keine Verwendung für die neueste FAANG-Technologie. Ihr Hauptanliegen ist entweder die Modernisierung von Legacy-Systemen oder endlich einen verlässlichen, automatisierten Zugang zu Daten zu haben, die sie heute mühsam manuell sammeln müssen.
Genau für diese Zielgruppe ist dieser Leitfaden gedacht. Wir konzentrieren uns auf das Wesentliche. Wir beleuchten Fallstricke und Fallen, die es zu vermeiden gilt. Du wirst in der Lage sein, Anbieter-Buzzwords zu erkennen, wenn sie Dir das nächste Mal aufgetischt werden.
Was Du von diesem Guide erwarten kannst
Statt von den neuesten Schlagworten geblendet zu werden, lerne ein Toolset kennen, das folgende Eigenschaften besitzt:
- Einfaches Setup und einfache Wartung
- Minimale Kosten bei hoher Nutzbarkeit
- Skalierbarkeit und die Fähigkeit, mit Ihren Use Cases zu wachsen
- Minimaler Vendor Lock-in
Nennen wir es den Minimalistischen Data Stack.

Die essentiellen Funktionen und unverzichtbaren Komponenten
Hinter all den Buzzwords ist der Zweck einer Datenplattform unverändert geblieben, seit die Inmons dieser Welt in den 1980er Jahren das Konzept des Data Warehousing entwickelten.
Im Kern wollen wir Daten aus verschiedenen operativen Systemen in einen zentralen Speicher verschieben, wo sie persistent gespeichert, bereinigt und gemäß unseren Geschäftsregeln transformiert werden, um sie dann für die weitere Nutzung bereitzustellen.
Diese einfache Aufschlüsselung ermöglicht es uns, die Komponenten unserer Datenplattform auf das absolute Minimum zu reduzieren:
1. Data Integration (Datenintegration)
2. Data Storage (Datenspeicherung)
3. Data Transformation (Datentransformation)

Die unverzichtbaren Komponenten (Non-Negotiables)
Darüber hinaus gibt es eine Klasse von Tools, die wir als "unverzichtbar" bezeichnen. Sie sind nicht zwingend erforderlich in dem Sinne, dass eine Datenplattform ohne sie noch erkennbar und funktionsfähig wäre. Aber wenn wir die drei Kernfunktionen als unser Fundament betrachten, dann sind die unverzichtbaren Komponenten die strukturelle Unterstützung, die es uns ermöglicht, mehr als ein Stockwerk hoch zu bauen.
Nur durch sie können wir unser Ziel einer wartbaren, skalierbaren und erweiterbaren Datenplattform erreichen:
1. Version Control (Versionskontrolle)
2. Documentation (Dokumentation)
3. Monitoring (Überwachung)

Sechs Komponenten für den robustesten Start. Würdest Du weitere hinzufügen, führst du zusätzliche Komplexität ein, die den Beginn Deiner Reise erschwert. Würdest etwas wegnehmen, riskiert die Integrität der Plattform einen erheblichen Schlag.
In den Worten von Antoine de Saint-Exupéry: "Perfektion ist nicht dann erreicht, wenn es nichts mehr hinzuzufügen gibt, sondern wenn es nichts mehr wegzunehmen gibt."
Warum Du dich von Komplettlösungen fernhalten solltest
Es gibt Anbieter, die Dich davon überzeugen wollen, dass ihre Lösung alle Ihre aktuellen und zukünftigen Bedürfnisse abdecken kann – und davon gibt es Millionen. Sei es Microsofts Push für Fabric, Plattformen wie Rivery oder Y42 oder branchenspezifische Lösungen wie Klar: Viele Lösungen existieren, die Dir einen sehr schnellen Start ermöglichen.
Entweder handelt es sich um No- oder Low-Code-Anwendungen, mit denen Du Ihre Pipelines und Transformationen per Drag & Drop erstellen kannst, oder sie bieten eine Ausführungsumgebung, Orchestrierung und Observability für die von Dir codierten Pipelines.
Die Versprechen dieser Anbieter sind verlockend. Aber in der Realität habe ich die Schattenseiten dieser Plattformen zu oft erlebt, um jemandem deren Nutzung empfehlen zu können.
Die Probleme mit No- und Low-Code-Lösungen
Die Theorie, Nicht-Datenexperten zu ermöglichen, Integrationen und Transformationen einfach und schnell einzurichten, klingt gut. Wer hat nicht schon in einem Unternehmen gearbeitet, in dem die IT-Abteilung ein Engpass war und mit Tickets kaum hinterherkam? Wenn die Teams, die auf die Daten angewiesen sind, diese selbst beschaffen können, klingt das auf dem Papier nach einer guten Idee.
Aber wenn Du darüber nachdenkst, klingt es nicht mehr so gut, Nicht-Datenexperten für Ihre Datenplattform verantwortlich zu machen. Sicher, eine kleine Automatisierung von zuvor manuellen Copy-Paste-Jobs in Excel-Tabellen mag machbar sein. Aber darüber hinaus skalieren diese Tools einfach nicht gut.
Entscheidende Transformationslogik und Geschäftsregeln hinter unzähligen Ebenen visueller Bausteine zu verstecken, ist schlichtweg nicht praktikabel, wenn man eine ernsthafte Plattform aufbaut, die mehr als nur einen Nischen-Use-Case bedienen soll. Kombiniere das mit oft fehlenden Features, die bei der Zusammenarbeit an Daten dringend benötigt werden – wie Versionierung oder automatisierte Deployment-Checks – und Du haast ein Rezept für eine Katastrophe.
Der letzte Sargnagel kommt in Form von Lock-in-Effekten. Wenn Du dich auf die visuellen Bausteine einer Plattform verlassen hast, um die gesamte Business Intelligence aufzubauen, wird der Wechsel zu einem anderen Tool aus irgendeinem Grund zur gefürchteten Aufgabe, da Du alles in dem neuen Tool neu aufbauen musst.
Das Problem mit "End-to-End"-Plattformen
Jede Plattform, die es Dir ermöglicht, Deinen eigenen Code auszuführen, ist ein Schritt in die richtige Richtung. Wenn Deine Data Assets in Code definiert sind, den Du besitzst, wird die Migration zu einer anderen Plattform, die diesen Code ausführen kann, um Größenordnungen einfacher, schneller und günstiger.
Dennoch bleibt für jede andere Funktion, die diese Komplettlösung bietet, der Lock-in-Effekt bestehen. Wenn Deine gesamte Fähigkeit, Daten in Deinem Unternehmen zu entdecken und zu dokumentieren, auf einem jährlichen Abonnement beruht, solltest Du besser hoffen, dass die Preise nicht steigen.
Willst Du wirklich darauf wetten, dass ein Anbieter bei jeder einzelnen Funktion Ihrer Datenplattform einen Volltreffer landet und die bestmögliche Lösung bietet? Nicht einmal die großen Namen kommen dem nahe. Microsofts Fabric mag clever vermarktet und zweifellos erfolgreich verkauft werden, ist aber berüchtigt dafür, wie schlecht es in der Data Engineering Community aufgenommen wird. Selbst das eigene Subreddit des Tools hält sich nicht zurück. Du wirst eine viel angenehmere Erfahrung machen, wenn Du eine modulare Zusammenstellung von Tools verwendst, die nachweislich gut zusammenarbeiten.
Die erforderlichen Fähigkeiten zum Aufbau einer Datenplattform
Auch mit dem Aufkommen von KI-Agenten und "Vibe Coding" erfordert der Aufbau und die Wartung einer Datenplattform spezifische Fähigkeiten. Nehme diesen Reddit-Thread als Beispiel dafür, warum Claude und Co. noch nicht für Data Engineering Jobs kommen werden.
Während also nicht jeder einfach eine Datenplattform ohne Aufwand zum Laufen bringen kann, kann jeder lernen, wie es geht. Und da wir mit so wenig Komplexität wie möglich beginnen (bei gleichzeitiger Beibehaltung eines skalierbaren Fundaments), ist es weniger herausfordernd, als Du vielleicht denkst.
SQL: Die Grundlage
SQL, die Abfragesprache, die erstmals das Licht der Welt erblickte, als Marvin Gaye vor mehr als 50 Jahren vorschlug, "Let's Get It On", bleibt die wichtigste Fähigkeit bei der Arbeit mit Daten. Im Minimalistischen Data Stack wird SQL verwendet, um Daten zu transformieren und Geschäftsregeln anzuwenden.
Python: Die zweite Säule
Nach SQL kommt Python. Wenn Du Daten aus operativen Tools in eine Datenplattform verschieben möchtest, wirst Du früher oder später auf Tools stoßen, die keinen automatisierten Datenexport zum Ziel Deiner Wahl unterstützen. In diesen Fällen hast Du zwei Optionen:
1. Maßgeschneiderte Anwendungen nutzen, die den Datentransfer für Dich übernehmen (kostspielig oder mit Verwaltungs- und Hosting-Aufwand verbunden)
2. Pipelines selbst programmieren
Während dies mit vielen Programmiersprachen möglich ist, ist Python die Wahl der meisten.
Weder SQL noch Python sind leicht zu meistern, aber beide gehören zu den einfacheren Programmiersprachen, die man erlernen kann. Daher sind sie äußerst beliebt, und mit dieser Popularität kommen reichlich Ressourcen zum Lernen und Üben. Diese Fähigkeiten sind auch leicht zu rekrutieren – ein Kriterium, das nicht zu vernachlässigen ist, wenn Du dich daran machst, eine Datenplattform aufzubauen, da Du auf dem Weg möglicherweise erfolgreich genug bist, um ein richtiges Datenteam aufzubauen.
Data Modeling: Das Rückgrat
Nicht zuletzt ist eine gewisse Vertrautheit mit Datenmodellierung erforderlich. Sehr selten liefern Rohdaten das, was wir von ihnen wollen. Wenn wir beginnen, Daten aus mehreren Quellen in ein zentrales Daten-Repository für unser Unternehmen zu kombinieren, ist es wichtig sicherzustellen, dass die Puzzleteile passen. Wenn das Datenvolumen wächst, stellt ein solides Datenmodell sicher, dass wir unsere Daten noch effizient abfragen können. Es ist das Rückgrat für hohe Datenqualität und verlässliche Erkenntnisse.
Die Tools, die unsere essentiellen Funktionen antreiben
Nach der Theorie ist es Zeit, die Architektur zusammenzustellen, die das Fundament unseres Data Stacks bilden wird.
Alle diese Tools sind in großen Datenprojekten erprobt. Sie sind aus gutem Grund Marktstandards. Und das Wunderbare ist, dass sie genauso gut für Einsteiger funktionieren. Mit diesem Fundament hast Du alles, was Du zum Wachsen brauchen.
Data Integration: dltHub
Wir könnten Komplettlösungen für die Datenintegration verwenden. Der Markt hat reichlich Optionen hervorgebracht, von Enterprise-Grade-Tools wie Fivetran bis hin zu Open-Source-Alternativen wie Airbyte. Diese Tools haben kleinere Nachteile, z.B. wenden sie jeweils ihr eigenes individuelles Schema auf integrierte Daten an, was den Wechsel zwischen Tools erschwert. Aber sie haben auch größere Nachteile: Bezahlte Tools sind teuer und machen Dich vom Anbieter abhängig, Open-Source-Tools erfordern Self-Hosting, was komplex werden kann, wenn Du sicherstellen möchtest, dass ordnungsgemäße Sicherheit gewährleistet ist.
Deshalb werden wir unsere Pipelines selbst schreiben. Das klingt einschüchternd, aber indem wir Python-Bibliotheken zum Verschieben von Daten nutzen, können wir erheblich Zeit und Aufwand einsparen. Unser Tool der Wahl wird dltHub sein.
Mit dlt profitieren wir von:
- Voller Flexibilität
- Vorgefertigten Konnektoren, die es uns ermöglichen, Daten schnell von Quellen zu Zielen zu verschieben
- Bestehenden Verbindungen für alle gängigen SQL-Datenbanken, REST APIs und eine Reihe gängiger operativer Anwendungen wie Salesforce, Shopify, Google Analytics oder Facebook Ads
- Automatischer Handhabung komplizierter Aspekte wie aktualisierte Daten und inkrementelle Ladevorgänge
dlt ist Open Source. Ihre Pipelines sind Python. Du kannst sie überall ausführen. Praktisch!
Data Transformation: dbt
Code ist König, auch bei Datentransformationen. Wir möchten explizit definieren, was mit unseren Daten geschieht, während sie durch das Data Warehouse laufen. Dies erreichen wir mit dbt.
dbt ist SQL auf Steroiden. Es ermöglicht uns, uns auf das Schreiben der SELECT-Anweisungen zu konzentrieren, die definieren, wie unsere Daten aussehen, und kümmert sich um die Erstellung der Tabellen, Views und Spalten, die dafür erforderlich sind. Die gesamte Transformation findet innerhalb unseres Datenspeichers statt.
Genau wie dlt für Integrations-Pipelines kümmert sich dbt um die Komplexität in unseren Transformationsprozessen:
- Aktualisierung von Daten
- Verfolgung von Änderungen
- Handhabung von Abhängigkeiten zwischen Objekten
All dies geschieht hinter den Kulissen, gibt aber dem neugierigen Geist die volle Kontrolle, den Vorhang beiseitezuschieben und ein Mitspracherecht zu haben.
Es ist Open Source. Es ist ein Kommandozeilen-Tool, das SQL-Anweisungen im Datenspeicher Ihrer Wahl ausführt. Du kannst es überall ausführen. Wieder praktisch!
Data Storage: Die triviale Wahl
Beim Aufbau einer Datenplattform erscheint der Ort, der Ihre Daten speichert und verarbeitet, wie der wichtigste Teil. Du wirst überrascht sein, dass dies in Wirklichkeit die trivialste Wahl im Minimalistischen Data Stack ist.
Bitte einen Deiner Kollegen, eine Zahl zwischen eins und drei zu wählen:
- Eins: Du entscheidst dich für Databricks
- Zwei: Snowflake wird Deine Wahl sein
- Drei: Google BigQuery (weil es sich reimt)
Natürlich ist dies stark vereinfacht, und jeder wird seinen eigenen Favoriten haben. Aber in Bezug auf Benutzerfreundlichkeit, Fähigkeit und Kompatibilität spielen alle drei in derselben Liga.
Entscheidungsfaktoren:
- Einige Unternehmen haben möglicherweise einen bevorzugten Cloud-Anbieter (Google Cloud Platform, Microsoft Azure oder Amazon Web Services), was die Wahl beeinflussen kann
- Databricks und Snowflake sind unabhängig und funktionieren in allen dreien
- BigQuery ist nur auf GCP verfügbar
Alle drei bieten kostenlose Credits oder Free Tiers, aber aus Erfahrung hat BigQuery das großzügigste. Tatsächlich stehen die Chancen gut, dass Ihr erster Use Case weit unter den kostenlosen Limits bleibt (10GB Speicher, 1TB Verarbeitung pro Monat).
Die unverzichtbaren Komponenten integrieren
Die Grundbausteine sind abgedeckt. Aber mit einigen Ergänzungen können wir sicherstellen, dass das, was wir jetzt aufbauen, auch langfristig performant und angenehm zu bedienen bleibt.
Version Control: GitHub
Da alle unsere Assets in Code definiert sind, ist Versionskontrolle ein Muss. Sie ermöglicht uns:
- Eine vollständige Historie aller jemals vorgenommenen Änderungen
- Entwicklung und Tests ohne Angst, den Produktionszustand zu zerstören
- Rückkehr zum Originalzustand bei Sackgassen
Wenn Du jemals in einem Tool gearbeitet hast, das dies nicht hat, kennst Du das nervenzerfetzende Gefühl, Änderungen speichern zu müssen, die sich direkt auf Ihre Produktionssysteme auswirken, ohne die Möglichkeit eines Rollbacks. Nein, danke.
Wir verwenden GitHub als unsere Versionskontrolle der Wahl.
Documentation: In dbt integriert
Erinnerst Du dich, wie wir uns vorgenommen haben, einen übersichtlichen Data Stack zu erstellen? Das Großartige an unseren bisherigen Tool-Entscheidungen ist, dass sie einige der unverzichtbaren Komponenten selbst handhaben können.
dbt verfügt über hervorragende Dokumentationsfunktionen:
- Visualisierung von Lineages zur Veranschaulichung, woher Daten kommen und wo sie verwendet werden
- Hinzufügen von Beschreibungen zu Tabellen sowie den enthaltenen Attributen und Metriken
- Kategorisierung von Daten mit Tags
- Hinzufügen beliebiger frei konfigurierbarer Metadaten zu Ihren Modellen
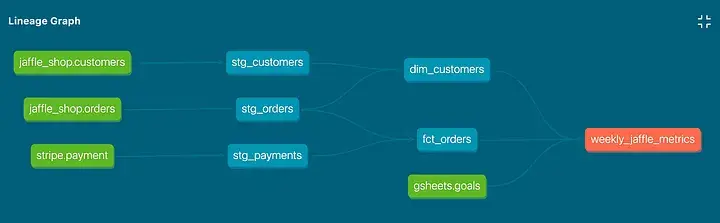
All dies ist einfach mit Ihren Stakeholdern teilbar, da dbt all dies in eine übersichtliche HTML-Seite verpackt, die leicht gehostet werden kann.
Monitoring: dbt-elementary
Wenn Daten zur Beeinflussung von Entscheidungen oder zur Steuerung von Prozessen verwendet werden, ist es entscheidend, dass den Daten vertraut werden kann. Du musst potenzielle Probleme im Blick behalten.
Auch hier helfen uns unsere Tool-Entscheidungen, schlank zu bleiben und Tool-Wildwuchs zu vermeiden. dbt kann mit Community-erstellten Paketen erweitert werden. Ein solches Paket ist dbt-elementary.
Was elementary leistet:
- Nutzt die Logs, die dbt beim Ausführen erstellt, und speichert sie neben Ihren Daten im Speicher
- Behält mit dieser Historie von Logs Ausführungszeiten, Modellfehler und Testabdeckung im Auge
- Ermöglicht erweiterte Tests zur Erkennung von Anomalien bei Modellausführungszeit, Datenvolumen und sogar auf Spaltenebene
Alle diese Erkenntnisse können direkt über Kommunikationskanäle wie Slack oder Teams gesendet und über HTML gehostet werden.

Alles zusammenbringen: GitHub Actions als Orchestrierung
Die sehr Aufmerksamen unter uns haben vielleicht bemerkt, dass wir bisher einen entscheidenden Aspekt eines Data Stacks nicht behandelt haben: Wo er tatsächlich läuft. Wie werden unsere Datenintegrations-Pipelines geplant und ausgeführt? Wie werden unsere dbt-Modelle aufgerufen?
Da wir es einfach und schlank halten, ist dies wieder eine Gelegenheit, Tools, die wir bereits verwenden, mehrfach zu nutzen.
GitHub bietet uns nicht nur das Repository, in dem wir unseren gesamten Code aufbewahren und versionieren. Es kommt auch mit einer wunderbaren Sache namens GitHub Actions.
GitHub Actions bietet Dir:
- Eine anpassbare Laufzeitumgebung zur Ausführung von Code
- Die Möglichkeit, Python-Skripte auszuführen und Kommandozeilen-Tools wie dbt aufzurufen
- Trigger oder zeitgesteuerte Zeitpläne zur Ausführung
- Ideale Voraussetzungen für unseren Use Case
Wir werden GitHub Actions nutzen, um sowohl unsere Python-Skripte zur Datenintegration auszuführen als auch dbt aufzurufen, um unsere Daten zu modellieren, sobald sie das Data Warehouse erreicht haben.
Kosteneffizienz: Jedes Repository kommt mit einer großzügigen Menge an kostenloser Nutzung für GitHub Actions. Alles hängt von der Häufigkeit und dem Volumen Ihrer Daten ab, aber wenn wir Daten einmal täglich im Batch verarbeiten, um ein paar Reporting-Dashboards zu füttern, bleiben wir sicher im kostenlosen Kontingent.
Fazit: Dein Fundament für nachhaltiges Datenwachstum
Du hast jetzt einen soliden Überblick über die Komponenten, die für den Aufbau einer Datenplattform unerlässlich sind. Du hast einen Tool-Stack kennengelernt, der ideal ist, um loszulegen, und gleichzeitig flexibel genug, um all Deine Anforderungen abzudecken, während Du über Deine anfänglichen Use Cases hinauswächst.
Die Vorteile auf einen Blick:
- Aufgrund seiner modularen Natur können Tools einfach ausgetauscht werden, wenn Alternativen Ihre Bedürfnisse besser erfüllen
- Da wir auf etablierte Lösungen setzen, spielen sie auch gut mit anderen Tools und Plattformen zusammen
- Ja, selbst KI-Use-Cases werden kein Problem sein, sobald Du das solide Fundament aufgebaut hast
Aber die Theorie ist nur eine Sache. Wo es wirklich interessant wird, ist die tatsächliche, praktische Implementierung. Und da wir darauf brennen, Dir beim Einstieg zu helfen, werden sich die nächsten Beiträge in dieser Serie genau darauf konzentrieren.
Möchtest Du erfahren, wie Du diese Architektur in Ihrem Unternehmen umsetzen kannst?
Bei The Data Institute haben wir bereits Dutzenden deutschen Mittelständlern geholfen, ihren Minimalistischen Data Stack aufzubauen – mit messbaren Erfolgen wie 87% Zeitersparnis bei MediaPrint oder 28% Conversion-Steigerung bei einem Regionalverlag.
Vereinbare jetzt Dein kostenloses Expertengespräch und lass uns gemeinsam Deine individuelle Data-Stack-Roadmap entwickeln.
Bereit für Ihren Minimalistischen Data Stack?
Ob Datenintegration mit dlt, Transformationen mit dbt oder die komplette Architektur – The Data Institute hilft deutschen Mittelständlern, schlanke und skalierbare Datenplattformen ohne unnötigen Tool-Wildwuchs aufzubauen. Vereinbare jetzt Dein kostenloses Strategiegespräch.
Bereit für Ihren Minimalistischen Data Stack?
Ob Datenintegration mit dlt, Transformationen mit dbt oder die komplette Architektur – The Data Institute hilft deutschen Mittelständlern, schlanke und skalierbare Datenplattformen ohne unnötigen Tool-Wildwuchs aufzubauen. Vereinbare jetzt Dein kostenloses Strategiegespräch.
Bereit für Ihren Minimalistischen Data Stack?
Ob Datenintegration mit dlt, Transformationen mit dbt oder die komplette Architektur – The Data Institute hilft deutschen Mittelständlern, schlanke und skalierbare Datenplattformen ohne unnötigen Tool-Wildwuchs aufzubauen. Vereinbare jetzt Dein kostenloses Strategiegespräch.
Passende Case Studies
Zu diesem Thema gibt es passende Case Studies


