Minimalist's Data Stack: Integrationspipelines mit dlt


Der Fahrplan für datengetriebene Transformation
Das ePaper zeigt dir Strategien, Erfolgsbeispiele und eine Checkliste für den direkten Start in die digitale Zukunft.

Die ersten Schritte zum Aufbau einer schlanken Datenplattform durch Zentralisierung Ihrer Daten.
Diese Reihe befasst sich mit dem Aufbau einer voll funktionsfähigen und dennoch schlanken Datenplattform, wobei hauptsächlich Open-Source-Tools zum Einsatz kommen, die sich vom Prototyp bis zur Unternehmensanwendung skalieren lassen.
- Teil 1: Die Grundlagen des Minimalist's Data Stack
- Teil 2: Einrichten von Integrationspipelines (dieser Teil)
- Teil 3: Automatisieren der Integration und Schreiben in den Speicher
- Teil 4: Entwerfen und Implementieren Ihres Datenmodells
- Teil 5: Hinzufügen von Dokumentation und Observability (wird noch veröffentlicht)
Der vollständige Code für diese Serie ist auf GitHub verfügbar.
Ein Blick auf den Blueprint
Werfen wir einen Blick auf den ersten grundlegenden Baustein des Minimalist's Data Stack. Wir werden dlt verwenden, um Daten in unseren Datenspeicher zu verschieben:
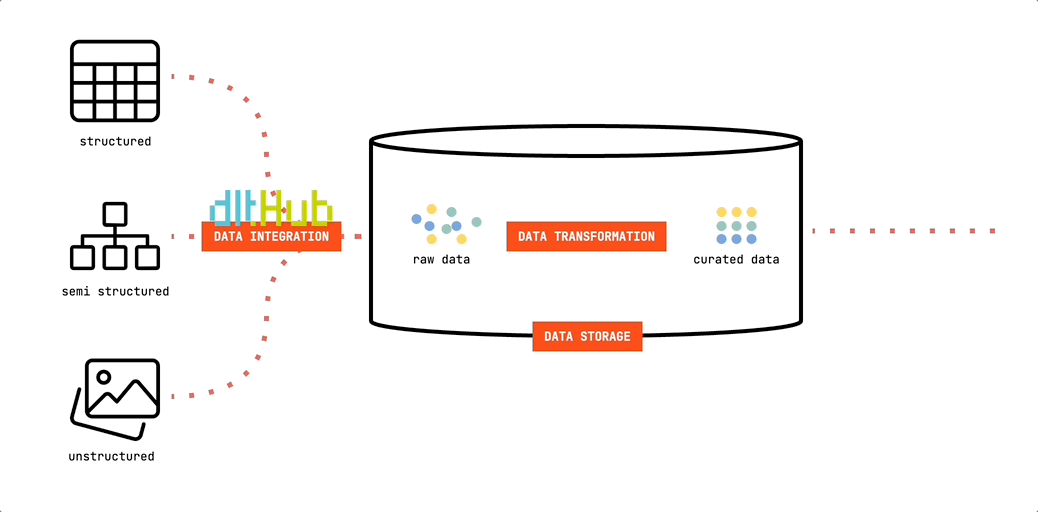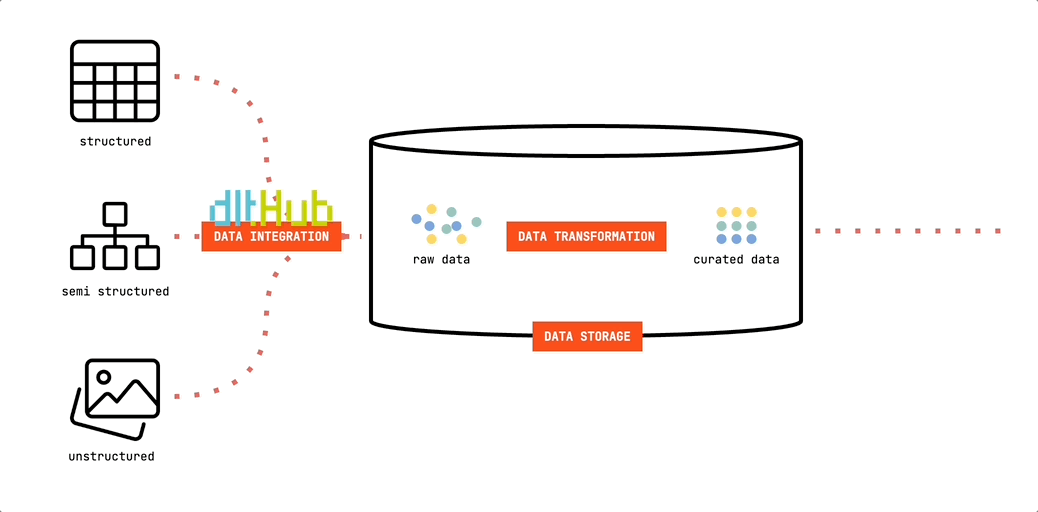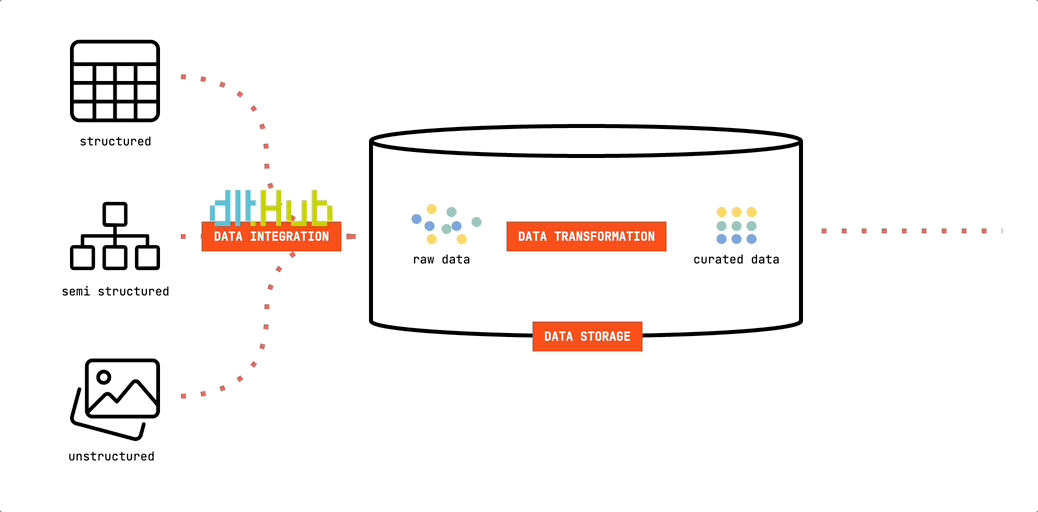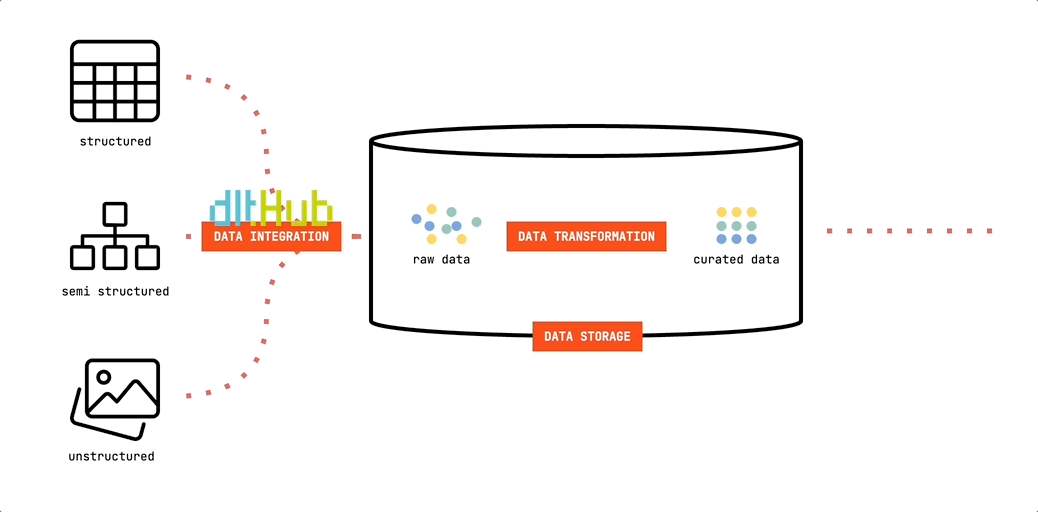
dlt (data load tool) ist eine Open-Source-Python-Bibliothek, die Schnittstellen zum Extrahieren von Daten aus APIs, Datenbanken, Cloud-Speichern oder einer Reihe häufig verwendeter Branchen-Tools wie Airtable, Google Ads und vielen anderen bietet.
Da es auf Python basiert, kannst du es in jeder Umgebung ausführen, die Python-Skripte ausführen kann. Dies bietet große Flexibilität. Du kannst Deine Pipelines ganz einfach auf Deinem Computer entwickeln und testen. Und sie lassen sich ebenso einfach auf Cloud-Ressourcen oder Orchestratoren wie Airflow, Dagster oder Prefect bereitstellen. In unserem minimalistischen Setup verwenden wir GitHub Actions, um unsere Pipelines auszuführen. Schlank. Und sogar ohne Lizenzkosten kostenlos.
Unser Anwendungsfall
Um das Beispiel so konkret wie möglich zu gestalten, werden wir die eigene Datenplattform des Data Institute neu aufbauen. Wir erzählen Dir hier also nicht nur von irgendwelchen zufälligen Technologien. Der betreffende Blueprint wird tatsächlich für unsere interne Analyse verwendet!
Wir sind ein Beratungsunternehmen. Daher muss jeder seine Arbeitsstunden erfassen, da die abrechenbaren Stunden unseren Kunden in Rechnung gestellt werden. Das Rückgrat unseres Betriebs ist MOCO, ein in der Schweiz entwickeltes ERP-System, das speziell für Agenturen konzipiert ist. Um Daten über die Aktivitäten unserer Mitarbeiter und die Projekte und Kunden zu erhalten, mit denen wir uns beschäftigen, verwenden wir die REST-API von MOCO.

Einrichtung unseres Python-Projekts
Unser Grundprinzip, Dinge von Anfang an richtig zu machen, gilt nicht nur für den Aufbau der Datenplattform selbst, sondern auch für jede ihrer Komponenten. Daher werden wir uv als Projekt- und Paketmanager für unser Python-Projekt verwenden. Wenn Du neugierig bist, warum das eine gute Idee ist, kannst Du in diesen Artikel von Thomas Bury nachlesen.
Wenn Du Python bereits installiert hast, kannst du pip verwenden, um uv zu installieren:
pip install uv
Andernfalls kannst Du auch curl auf Mac und Linux verwenden, um das Installationsskript herunterzuladen und auszuführen:
curl -LsSf https://astral.sh/uv/install.sh | sh
Unter Windows installierst Du es mit PowerShell:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Weitere Informationen findest Du in der Dokumentation von uv: Installation.
Initialisiere ein neues uv-Projekt
Mit uv initialisieren wir ein Projekt namens dlt-pipeline:
uv init dlt-pipeline
Dadurch wird eine einfache Projektstruktur erstellt:
dlt-pipeline
├─ .python-version
├─ main.py
├─ pyproject.toml
└─ README.md
Wir können main.py direkt löschen – wir werden es nicht verwenden. README.md wird später unsere Projektbeschreibung enthalten. pyproject.toml ist eine Zusammenfassung unseres Python-Projekts und verfolgt auch alle Abhängigkeiten des Projekts. Derzeit gibt es keine.
Installiere dlt
Mit uv fügen wir dlt als Bibliothek hinzu, die in unserem Projekt verwendet werden soll:
uv add dlt
Du wirst feststellen, dass uv die Bibliothek automatisch zu den Abhängigkeiten unseres Projekts in pyproject.toml hinzufügt. Wenn jemand anderes dieses Projekt mit uv ausführen würde, würden alle diese Abhängigkeiten automatisch installiert werden. Dies erleichtert die gemeinsame Nutzung von Projekten und die Zusammenarbeit erheblich.
uv hat nun auch eine virtuelle Umgebung für unser Projekt erstellt: Du wirst hierbei feststellen, dass ein Ordner .venv erschienen ist. Alle Abhängigkeiten unseres Projekts sind dort installiert, sodass Deine globale Python-Installation sauber bleibt.
Einrichten unseres dlt-Projekts
Nun ist es an der Zeit, Dein Python-Projekt in ein dlt-Projekt umzuwandeln. Dazu erstellen wir zwei Ordner in unserem Repository: .dlt und sources.
Der erste Ordner enthält Konfigurationsdateien und speichert Secrets, der zweite enthält unseren eigentlichen Pipeline-Code.
Im Ordner .dlt erstellen wir zwei Dateien namens config.toml und secrets.toml. In sources erstellen wir eine Datei namens moco_pipeline.py.
Da wir mit Secrets arbeiten und vermeiden möchten, dass diese versehentlich in unserem Repository gespeichert werden, sollten wir sicherstellen, dass wir secrets.toml auch zu unserer .gitignore-Datei hinzufügen.
Überprüfe die Projektstruktur
Zu diesem Zeitpunkt sollte Dein Projekt alle folgenden Dateien enthalten:
dlt-pipeline
├─ .dlt
│ ├─ config.toml
│ └─ secrets.toml
├─ .venv
├─ sources
│ └─ moco_pipeline.py
├─ .gitignore
├─ .python-version
├─ pyproject.toml
├─ README.md
└─ uv.lock
Da uv auch automatisch eine Reihe von Dateien und Ordnern erstellt hat, nehmen wir uns einen Moment Zeit, um die derzeit in unserem Projekt enthaltenen Dateien zu überprüfen:
.dltundsecrets.toml: Dieser Ordner enthält Konfigurationsdateien für dlt. Er sucht insecrets.tomlnach den Credentials, die für den Zugriff auf unsere Datenquellen und -ziele erforderlich sind..venv: Dieser Ordner enthält unsere installierten Bibliotheken. Wir müssen ihn nicht anfassen oder weiter darüber nachdenken, dauvalles für uns erledigt.sourcesundmoco_pipeline.py: Wir verwenden einen speziellen Ordner, um unseren Pipeline-Code zu speichern. Jede Pipeline erhält eine eigene.py-Datei. Auf diese Weise können wir unser Projekt auch dann übersichtlich halten, wenn wir mehrere Pipelines hinzufügen..gitignore: Diese Datei teilt unserer Versionskontrolle mit, welche Dateien davon ausgeschlossen werden sollen. Ein Teil ihres Inhalts wird vonuvausgefüllt, andere Teile (wiesecrets.toml) sollten wir hinzufügen..python-version: Teiltuvmit, welche Python-Version unser Projekt für seine virtuelle Umgebung verwendet. Wir müssen diese Datei nicht anfassen.pyproject.toml: Fasst unser Projekt zusammen. Wenn wiruvzum Hinzufügen von Bibliotheken verwenden, verfolgt es unsere Abhängigkeiten für uns.README.md: Ermöglicht es uns, anderen oder uns selbst in Zukunft Anweisungen zur Verwendung des Projekts zu geben. Nutze diese Datei als Übung, um das in diesem Leitfaden Gelernte noch einmal zu wiederholen!uv.lock: Ist eine weitere Datei, die automatisch vonuvgeneriert wird. Sie wird vonuvverwendet, um die genaue Konfiguration, die Du habst, auf verschiedene Installationen des Projekts zu übertragen. Diese Datei sollten wir nicht anfassen.
Extrahieren von Daten aus unserer REST-API-Quelle
Durch die Verwendung der REST-API-Quelle von dlt müssen wir das Rad nicht neu erfinden. Stattdessen erhalten wir eine Vorlage, die wir schnell an unsere Bedürfnisse anpassen können und mit der wir innerhalb weniger Minuten Daten aus unserer Quelle extrahieren können. Sie funktioniert mit jeder REST-API, selbst mit Nischen-APIs wie unserer Agentur-ERP-Anwendung.
Wir werden nun Schritt für Schritt unsere Datei moco_pipeline.py im Ordner sources erstellen.
Importieren der erforderlichen Bibliotheken
import dlt
from dlt.sources.rest_api import RESTAPIConfig, rest_api_resources
from datetime import datetime
Wir importieren die Hauptbibliothek von dlt.
Außerdem importieren wir bestimmte Klassen für die Arbeit mit REST-API-Datenquellen: RESTAPIConfig ist eine Konfigurationsklasse, mit der wir definieren können, wie wir eine Verbindung zu REST-APIs herstellen und Daten daraus extrahieren. rest_api_resources ist eine Funktion, die dlt-Ressourcen aus REST-API-Endpunkten basierend auf der von uns bereitgestellten Konfiguration erstellt.
datetime ist eine Standard-Python-Bibliothek für die Arbeit mit Uhrzeiten und Datumsangaben. Wir werden diese verwenden, um zu steuern, welche Zeiträume der Daten extrahiert werden.
Definiere die dlt-Quelle
Jetzt müssen wir unsere REST-API-Quelle definieren. Wir werden sie zunächst Stück für Stück aufschlüsseln, bevor wir sie vollständig zusammenfügen.
@dlt.source
def moco_source(api_key=dlt.secrets.value):
initial_value = "2024-04-01T00:00:00Z"
today = datetime.now().strftime("%Y-%m-%d")
Wir beginnen mit der Definition einer Funktion namens moco_source() mit einem api_key-Parameter, dessen Wert aus der Secret-Verwaltung von dlt abgeleitet wird. Wir verwenden den @dlt.source-Decorator, um diese reguläre Funktion als dlt-Datenquelle zu registrieren. Diese Funktion muss in Pipelines verwendet werden.
Anschließend definieren wir zwei Variablen, die in der Funktion verwendet werden sollen. initial_value bezeichnet unseren Startpunkt. Es handelt sich um das Datum, an dem das Data Institute offiziell seinen Betrieb aufgenommen hat, aber wir hatten bereits vorher Zeitbuchungen. Diese möchten wir ignorieren. today enthält einfach das aktuelle Datum und hilft uns, "zukünftige" Buchungen herauszufiltern, da einige unserer Mitarbeiter bereits Meetings und Veranstaltungen in ihren Kalender eingetragen haben.
config: RESTAPIConfig = {
"client": {
"base_url": "https://thedatainstitute.mocoapp.com/api/v1",
"auth": {
"type": "bearer",
"token": api_key,
}
},
...
Wir definieren nun eine Variable config vom Typ RESTAPIConfig, die wir zuvor aus dlt importiert haben. Der Wert der Variable ist ein Python-Dictionary.
Der erste Eintrag im Dictionary ist client, selbst ein weiteres Dictionary. Es definiert unseren REST-API-Client, welche Base-URL verwendet werden soll und wie die Authentifizierung gehandhabt werden soll. Wir verwenden ein Bearer-Token und erhalten den Wert aus dem api_key-Parameter der Funktion. Denke daran, dass dieser auf die Secret-Verwaltung von dlt verweist.
...
"resource_defaults": {
"primary_key": "id",
"write_disposition": "append",
},
"resources": [
{
"name": "users",
"write_disposition": "replace",
"endpoint": {
"path": "users",
}
},
{
"name": "activities",
"endpoint": {
"path": "activities",
"params": {
"updated_after": "{incremental.start_value}",
"from": "2024-04-01",
"to": today
},
"incremental": {
"cursor_path": "updated_at",
"initial_value": initial_value
}
},
},
...
resources sind die Bezeichnung von dlt für die verschiedenen Endpunkte, die wir in einer REST-API abfragen möchten.
Wir haben resource_defaults definiert, die standardmäßig auf alle Ressourcen angewendet werden sollen. In unserem Fall handelt es sich dabei um die Festlegung eines Primary Keys für jede Datenzeile sowie um die Standard-Write-Disposition: Bei jedem neuen Durchlauf unserer Pipeline möchten wir die neu abgerufenen Daten an die bereits vorhandenen Daten in unserem Ziel anhängen.
Anschließend geben wir eine Liste der Endpunkte an, die wir als Ressourcen abfragen möchten: users und activities.
Unser users-Endpunkt ist sehr einfach. Seine Response enthält Daten zu unseren Mitarbeitern. IDs, Namen, Adressen. Da wir ein kleines Unternehmen sind, ist die Anzahl der User sehr begrenzt. Aus diesem Grund müssen wir uns hier nicht um das inkrementelle Laden von Daten kümmern. Wir können die Daten in unserem Ziel einfach jedes Mal überschreiben, wenn unsere Pipeline ausgeführt wird. Daher überschreiben wir unsere Standardkonfiguration und setzen "write_disposition": "replace". path teilt dlt lediglich mit, welcher Pfad an die base_url angehängt werden soll, die wir zuvor im client-Teil definiert haben.
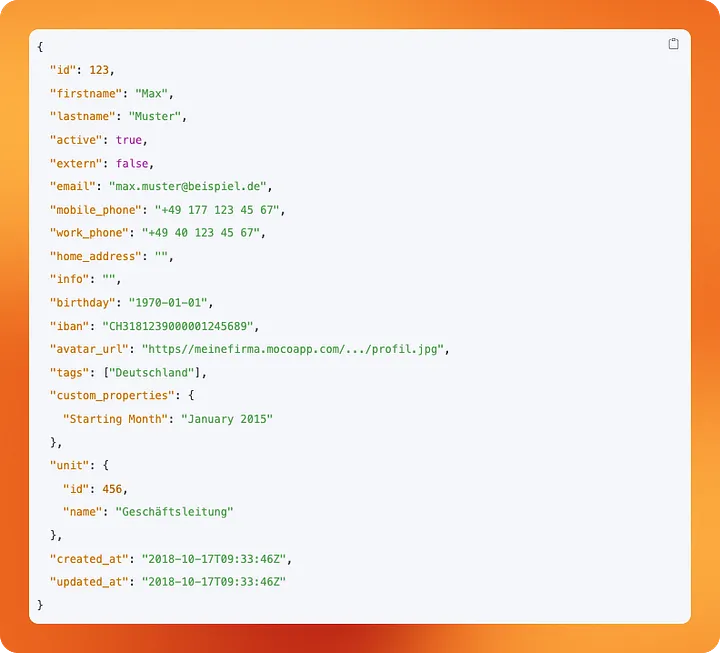
Die Ressource activities ist etwas interessanter. Da wir jedes Jahr Tausende von Activities verfolgen, möchten wir bei der Abfrage dieses Endpunkts etwas ressourceneffizienter vorgehen. Anstatt ständig alle Daten abzufragen, möchten wir nur die Daten abfragen, die seit unserem letzten Pipeline-Lauf aktualisiert wurden. Zu diesem Zweck können wir mit dlt inkrementelle Ladevorgänge für Ressourcen konfigurieren.
Schauen wir uns den incremental-Teil an. dlt verwendet die Spalte, die wir als cursor_path angegeben haben, um zu verfolgen, welche Daten bereits geladen wurden. Bei jedem Lauf der Pipeline wird die Spalte updated_at überprüft und der höchste Wert für zukünftige Referenzzwecke gespeichert. Mit initial_value können wir dlt mitteilen, wo es beim allerersten Lauf der Pipeline beginnen soll.
Als Nächstes müssen wir diese Konfigurationen als Parameter in unserer Abfrage verwenden. Die API von MOCO ermöglicht es uns, Daten zu filtern, die nach einem als updated_after-Parameter angegebenen Zeitstempel aktualisiert wurden. Hier verweisen wir auf {incremental.start_value}. Bei der Ausführung der Pipeline füllt dlt diesen Wert mit dem neuesten Wert aus unserem cursor_path. Auf diese Weise fragen wir nur Daten ab, die nach dem letzten Lauf unserer Pipeline aktualisiert wurden.
Zusätzlich verwenden wir die Parameter from und to, um Activities auszuschließen, die vor unserer Unabhängigkeit als Unternehmen stattfanden oder in der Zukunft stattfinden werden, da einige von uns gerne ihren Zeitplan im Voraus buchen.

Zu guter Letzt:
yield from rest_api_resources(config)
Wir rufen die Funktion rest_api_resources() von dlt auf. Dadurch wird jedes Element unserer resources-Liste in der Variable config in eine tatsächliche dlt-Ressource umgewandelt. Wir geben diese per yield zur Verwendung in einer dlt-Pipeline zurück.
Erstelle eine Pipeline, die unsere Quelle verwendet
Das Erstellen einer Pipeline ist sehr einfach.
def load_moco() -> None:
pipeline = dlt.pipeline(
pipeline_name="moco-to-local",
destination="filesystem",
dataset_name="moco"
)
load_info = pipeline.run(moco_source(), loader_file_format="csv")
print(load_info)
Wir definieren eine Funktion load_moco() und erwarten nicht, dass sie etwas zurückgibt. Wir kennzeichnen dies mit -> None.
Innerhalb der Funktion erstellen wir eine Pipeline mit dem Namen moco-to-local. Wir deklarieren ein Destination. Da wir noch nicht über Data Storage sprechen, bleiben wir beim filesystem. Dadurch können wir Daten lokal speichern und sie nach dem Ausführen unserer Pipeline zum Testen leicht überprüfen. dataset_name definiert, unter welchem Ordner oder Schema Daten im Destination gespeichert werden sollen.
Wir führen unsere Pipeline mit .run() aus und übergeben dabei unsere zuvor erstellte dlt-Source-Funktion. Wir geben auch an, in welchem Format unsere extrahierten Daten gespeichert werden sollen. Normalerweise wäre dies beispielsweise Parquet, aber vorerst bleiben wir bei CSV, da dies die Überprüfung der Daten erleichtert.
Hinzufügen von Config und Secrets
Es ist an der Zeit, uns die beiden .toml-Dateien im .dlt-Ordner anzusehen, die wir zuvor erstellt, aber bisher noch nicht verwendet haben.
Wenn wir eine universell gültige Konfiguration zu einer unserer dlt-Pipelines hinzufügen möchten, speichern wir diese in der Datei config.toml. Wenn unser Projekt wächst und wir eine Pipeline nach der anderen hinzufügen, möchten wir nicht immer wieder dieselben Dinge konfigurieren. Stattdessen speichern wir sie hier und wenden sie auf unser gesamtes Projekt an.
Um die Überprüfung unserer Daten während der Arbeit an unserer Pipeline zu vereinfachen, können wir hier die folgende Konfiguration hinzufügen:
[normalize.data_writer]
disable_compression=true
Dadurch wird sichergestellt, dass die CSV-Dateien, die wir schreiben, für uns lesbar sind, indem wir sie einfach öffnen. Normalerweise würde dlt eine Komprimierung anwenden, um die Speichereffizienz zu erhöhen, aber darum geht es uns hier noch nicht.
Im Gegensatz zu config.toml ist die Datei secrets.toml etwas, das nicht mit anderen geteilt werden sollte. Sie enthält Passwörter, API-Keys und andere sensible Daten, die für den Betrieb unserer Pipelines erforderlich sind.
In unserem Fall enthält sie unseren MOCO-API-Key und den Dateipfad, in den unsere Daten geschrieben werden sollen:
[sources.moco_pipeline]
api_key = "<redacted>"
[destination.filesystem]
bucket_url = "data"
Nachdem wir unsere Konfiguration und Secrets hinzugefügt haben, sind wir nun bereit, unsere Pipeline zum ersten Mal auszuführen.
Ausführen der Pipeline
Da alles übersichtlich in einer Python-Datei zusammengefasst ist, ist die Ausführung der Pipeline so einfach wie das Ausführen eines Python-Skripts:
uv run sources/moco_pipeline.py
Wenn wir unsere Secrets und Config korrekt konfiguriert haben, hat dlt einen data-Ordner in unserem Repository erstellt. Darin findest Du einen Ordner für jede unserer erstellten Ressourcen sowie einige Daten, die dlt verwendet, um den Status der Pipeline zu verfolgen.
Wenn wir uns den Ordner data/activities/ ansehen, finden wir eine CSV-Datei mit allen unseren erfassten Arbeitsstunden seit Gründung des Unternehmens.
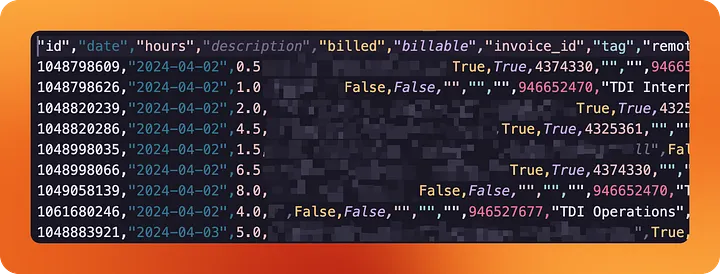
Wenn Du Python verwendst, um Daten aus den Tools Deines Unternehmens zu extrahieren, könnte es kaum einfacher sein.
Zusammenfassung
Wir haben unsere erste dlt-Pipeline konfiguriert, um Daten aus dem ERP-Tool unserer Agentur zu extrahieren. Das ist ein wichtiger erster Schritt, aber damit allein ist eine Datenplattform noch nicht fertig.
Anstatt Daten in unser lokales Filesystem zu schreiben, möchten wir sie in einem geeigneten Data Storage ablegen, wo sie analysiert und mit anderen geteilt werden können. Die Pipelines müssen auch automatisch ausgeführt werden, da wir nicht jeden Tag manuell das Python-Skript ausführen möchten.
Wir werden uns mit diesen Themen in den nächsten Artikeln dieser Serie befassen, nach deren Lektüre bist du in der Lage , selbst eine schlanke und effiziente Datenplattform einzurichten. Vollständig in Deinem/Euren Besitz, ohne Vendor Lock-in.
Den Code für diesen und alle anderen Artikel dieser Serie findest Du auf GitHub.
Dein eigener Modern Data Stack – ohne Lizenzmonster
Diese Serie an Artikeln zeigt Dir, wie mächtig Open Source sein kann. Aber der Weg vom ersten Python-Skript zur sicheren Enterprise-Plattform ist oft komplexer als gedacht.Wir planen und bauen Deine skalierbare Dateninfrastruktur: Kosteneffizient, wartbar und basierend auf Modern Best Practices (dbt, dlt, Python).
Vom Prototyp zur Produktion: Lass uns gemeinsam prüfen, ob ein "Minimalist Stack" auch für Deine Anforderungen die richtige Lösung ist.
👉 Lass uns Deine Architektur planen (Infrastructure & Engineering)
Bereit für Ihre eigene schlanke Datenplattform?
Erfahren Sie in einem kostenlosen Erstgespräch, wie Sie mit dem Minimalist's Data Stack schnell und effizient Ihre Datenintegration aufbauen – maßgeschneidert für Ihr Unternehmen.
Bereit für Ihre eigene schlanke Datenplattform?
Erfahren Sie in einem kostenlosen Erstgespräch, wie Sie mit dem Minimalist's Data Stack schnell und effizient Ihre Datenintegration aufbauen – maßgeschneidert für Ihr Unternehmen.
Bereit für Ihre eigene schlanke Datenplattform?
Erfahren Sie in einem kostenlosen Erstgespräch, wie Sie mit dem Minimalist's Data Stack schnell und effizient Ihre Datenintegration aufbauen – maßgeschneidert für Ihr Unternehmen.
Passende Case Studies
Zu diesem Thema gibt es passende Case Studies

Welche Leistungen passen zu diesem Thema?